Welcome back. In this article we'll be discussing the finer points of tag systems that we will need to emulate, not to mention emit code for. For a bit more context check out the introduction.
Preface
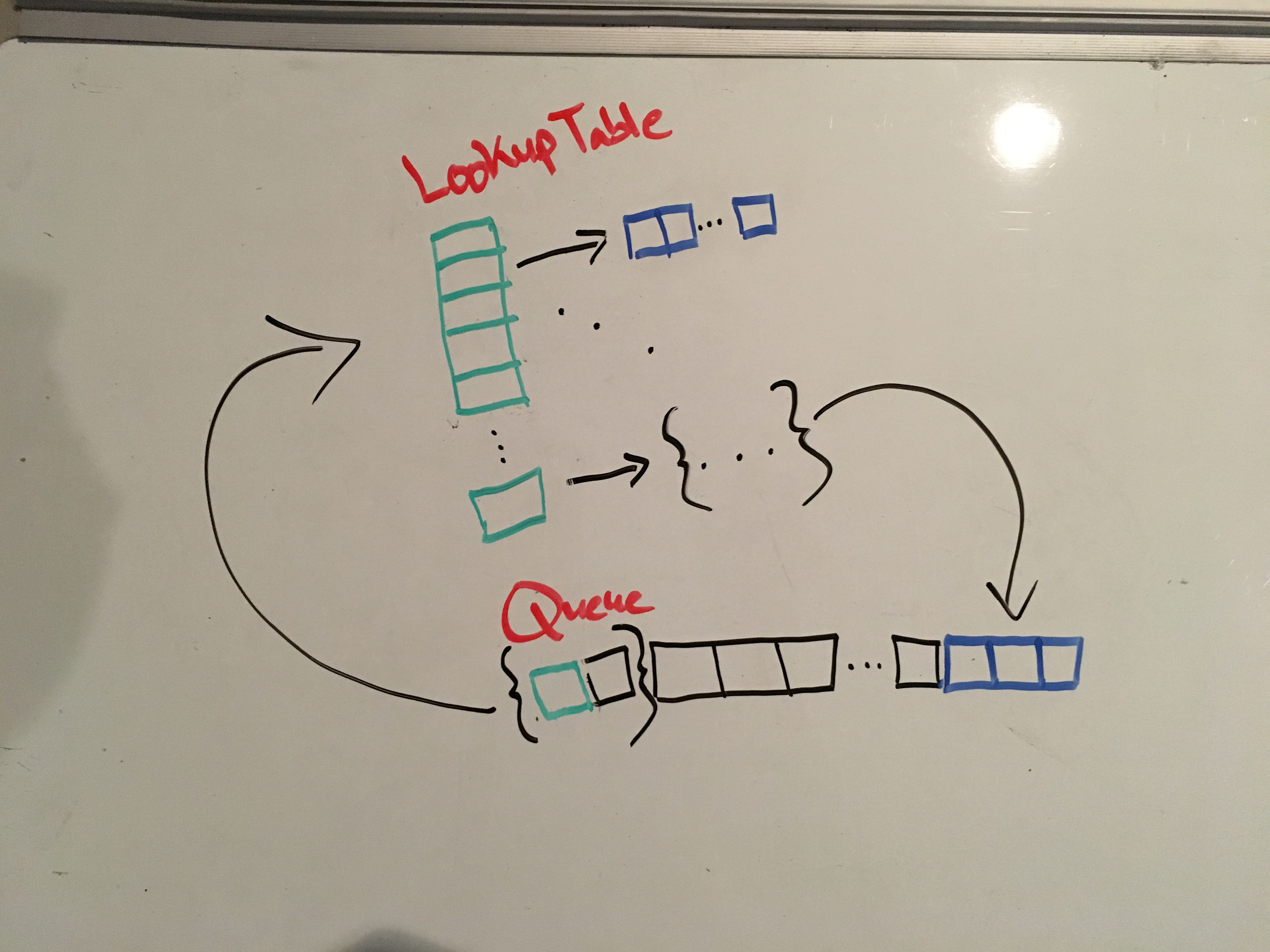
What ARE these tag systems anyway? In the most relatable terms I can think
to describe them: tag systems consist of a lookup-table and a queue that
interact in exactly one way, via popping off a fixed number of elements from
the queue, using the very first element as the key in the table, and appending
the corresponding value back to the end of the queue. This means that the
computation step is {pop, lookup, append}. The number of elements
to dequeue during the computation step is fixed for a given tag system. The
proper way to interpret these structures is that the queue is program data
while the table is program code. This is a harvard architecture.
We will rapidly delve into the nitty gritty but I want to first give some terminology. If you read through the code you'll notice many different terms for the same ideas. The lookup table is implemented as a hashmap and was named "productions". The keys in this table are normally referred to as symbols or rules. The corresponding values are usually called appendants or productions. The key-value pairs tend to be called productions or, also, rules.
As for the tag system itself, it has a few parameters. To be very formal we
have a deletion-number, a finite alphabet, and a set or productions. The
deletion-number is how many symbols to pop from the data queue, the finite
alphabet defines what constitutes a symbol, and the productions are the rules
that form the lookup table. For our purposes we can think of a compiler or
interpreter trying to consume some source file. In this light, the finite
alphabet is just what constitutes all valid identifiers for a variable which
means that symbols are simply variables. As for the deletion number, it must be
at least 2 (any guesses as to why?). We'll specialize and just use 2 forever.
This means we are only dealing with 2-tag systems. And the productions are just
plain old {symbol: [symbol]} which we know how to handle from more
traditional languages.
One other thing before we begin, I want to apologize for my sloppy terminology. Hopefully it is obvious from the context of the code what is what but if not, that's my fault. Re-using terms has the side-effect that explaining things in writing is a bit more tedious. But I have no one to blame but myself.
Baby Steps
With some terms defined we can now journey into the tag system proper. Here's an example program (taken from wikipedia):
Deletion number: 2
Table:
rule -> {appendant}
a -> c c b a H
b -> c c a
c -> c c
Queue:
0: b a a
1: a c c a
2: c a c c b a H
3: c c b a H c c
4: b a H c c c c a
5: H c c c c a c c a
ERROR: Unknown rule
The queue is evolving by a single tag machine step at each iteration (shown as
distinct lines above) with the initial value displayed at iteration 0. Don't
worry about the content, or semantic meaning, of these rules for the moment
(spoiler alert: in this example they are meaningless). Ensure that you
understand why each new iteration must be the displayed value. For the moment
we are just trying to build some rote technical muscle. To elaborate, we delete
(or pop from the queue) two values at a time. Initially these values are {b,
a}, the leading elements of the queue. What remains is a lonely symbol a. We
then use the very first deleted value b to lookup the corresponding
production: {c, c, a}. This production is appended to the queue resulting in:
{a, c, c, a}. This process repeats until it can't, for some reason. In this
particular implementation we halt if we can't find the key which occurs when
looking up the production for the symbol H. Another reason to halt is when
the queue is too small (or empty). Something to note, we "delete" 2 elements
from the queue at each step but only the very first element is used. The other
element is discarded and has absolutely no effect. If our deletion number were
3 then we would pop off 3 elements but we would still only use the first one as
the key.
Ok, great. So what? In the wikipedia article they compute some collatz sequences (I'll spare the example) but this technique hardly scales. How can I add 1+1? Better yet, how can we program the tag machine? Before answering such questions, let's first examine what exactly we're asking about. What makes a system universal, or turing complete? The obvious answer is "someone proved it". And that sounds like as good a path as any to pursue so let's take a look at Hao Wang's proof that tag systems are indeed programmable.
Let me preface by saying, this paper is fantastic. The dude wastes no time and presents a neat representation of a turing machine before dumping a series of rules to emulate it with tag instructions. But it looks like it is time for a detour because he emulates a particular flavor of turing machine. So here we go, let's learn about Wang's b-machine!
B-Machines
This paper is titled "A Variant to Turing's Theory of Computing Machines" and introduces a very simple machine indeed. The b-machine has only 4 instructions. To understand the instructions we need to know how we store data. In typical turing-machine fashion we have an unbounded tape (i.e., infinite memory). This tape is initially empty (i.e., the whole thing is filled with infinite zeroes). There is only one "register" which is a pointer to a particular bit on the tape which is "initialized" to the "middle" of the tape. We can only access the tape via manipulations of this register. The instructions available to us include: (1) seek the head (i.e., the register containing the pointer to the tape) to the right by a single bit, (2) seek the head to the left by a single bit, (3) write a 1 bit to the head, and finally (4) conditionally branch. Conditional transfer checks the bit under the head, if it is set then we branch to a constant offset encoded in the instruction, otherwise we "fallthrough" and execute the next instruction. Notice that the b-machine is incapable of writing a zero bit! We can (probably, I don't actually know the method) overcome this by copying all of the state over to a new section of the (still zeroed) tape, but boy that seems super awful.
The nice thing about this machine, however, is that it is incredibly simple. We don't have to worry about abstract symbols (we only are allowed 0 and 1 only), we needn't worry about bounds of the tape (we can seek arbitrarily in either direction), and some other stuff that more elaborate turing-machine representations use. This means that we can emulate it in a much more straight forward fashion. The obsessive reader will notice that the tag system paper contains an erase instruction. What in the world!? Thankfully there is a variant of the b-machine termed the w-machine which is a strict superset adding a single instruction: (5) write a 0 bit to the head.
To summarize, we can increment or decrement the head, set a 0 or 1 bit, and conditionally branch given the bit under the head. This seems incredibly similar to a language called brainfuck. And it is. It is essentially 1-bit brainfuck but with a nicer branching mechanism (loops are too constraining!). And since we have another language, let me layout the syntax:
+: Set the bit under the head (write a 1)
-: Clear the bit under the head (write a 0)
>: Seek the head to the right
<: Seek the head to the left
jmp TrueLabe{, FalseLabel}: Conditionally branch in the flavor of if-else!
Here's a simple program that ensures the tape is filled with 1s.
0: top:
0: +
1: >
2: jmp top, top
Later on it should be apparent why I added the ability to branch to two separate locations. I must stress that this doesn't diminish anything. We could simulate the if-else behavior if we didn't have it with a few instructions. You might also curse me for using "jmp" when it is conditional. And that's alright.
Now that we understand the machine we will be emulating with the tag system, we can finally get back to Wang's universality proof. Can you think of a way to implement any of those instructions given the programming style of the tag system? Let's take a look at how Wang went about it.
As an aside, check out emu/tag.py. I didn't use this exact program from the onset but I definitely used it to debug tag rules later on. I think playing around with it to develop an intuition would be helpful for the next part.
Wang's W-Machine Representation
But I digress, at least now we can resume our examination of Wang's universality proof given in the paper "Tag Systems and Lag Systems". Wang begins by giving us a remarkably elegant representation of the w-machine: (xi xi)m (si si) (yi yi)m. The reason each symbol (x, s, and y) are duplicated is due to the fact that we are using a 2-tag system which means we delete 2 symbols per computation step. The subscripts are there to track which w-machine instruction we're currently emulating. Moving deeper, we can decode the three parts as: the tape to the left of the head (x's, or sometimes a's), the value of the head (s's), and the tape to the right of the head (y's, or sometimes b's). You can also think of this as two queues (one for each side of the infinite tape), and the value of the head. The tape representation is implicit and indirect. We don't encode each bit with a particular symbol but instead use the count of the symbols to be the binary representation of the tape. In other words, it's a unary representation. To elaborate, imagine we have the tape 101 (forget about different sides of the tape for a minute). This means that there are two 1 bits and the rest are (explicitly or implicitly) zero. 101 can also be thought of as the numeral 5. This means the tape would consist of 5 "symbols", say x x x x x. In reality, it would be 2*5=10 due to the deletion number—or x x x x x x x x x x—but the key idea is that the symbols themselves are absolutely meaningless. It is only in aggregate that the w-machine's value is given form. Pretty neat. One thing with this representation to keep in mind is that it is unary meaning exponentially more memory per bit of state. Keep this in mind.
But what is with the subscripts? The answer links, in a very deep way, the
rules generated by our compiler and the instructions being emulated. The tag
system does not have an instruction pointer, it is just a jumble of rules. The
subscripts enable us to partition the rules into namespaces corresponding to
each emulated instruction. Taking the initial w-machine program as our example
we see that is consists of 3 instructions. Let's just assume that it will take
more than one tag system rule to implement any given w-machine instruction.
This means the tag system must transform its state not just from instruction_0
to instruction_1 directly but slowly via perhaps sub-instruction_0' to
sub-instruction_0'' to instruction_1. Remember, we're just emulating
complicated operations from simple primitives so naturally it's just a
transformation of some data from one state to another to another.
Getting Our Hands Dirty
Let's make this more concrete and actually implement "+" in the tag system. Say
we have the "initial" w-machine state of all zeroes. Again, the w-machine state
is represented entirely by: (xi xi)m
si si (yi yi)n. This
means it'll look like: (x0 x0)0 s0
s0 (y0 y0)0. More succicntly, just:
s0 s0. Ah, let me detour just a little bit more :)
What is s0? s0 is a
placeholder. s0 means either 10
or 00 (notation taken directly from the paper). I
believe it means "scanned value". This is in contrast with the two sides of the
tape which are represented by the count of the symbols, here we instead get to
be very direct and display the value itself. This looks confusing so let's
rewrite those as s10 or s00.
Let's drop the subscripts for the moment since we are explicitly talking about
the very first instruction. Without subscripts we then have s as a placeholder
for s1 or s0. This is simply a bit! From here on out I won't use the
paper's s and will instead be explicit and use s0 and s1. "Ok, but bits
on my machine don't have subscripts, what is that all about?" Remember that the
tag system is EMULATING the w-machine. The tag system has no concept of bits or
state. It has to explicitly keep track of where the w-machine is in order to
faithfully reproduce its operations. This involves tracking every single state
transition. The subscripts explicitly reference which w-machine instruction is
currently executing. This has massive implications for the efficiency of our
implementation. The full magnitude of this is sure to force out a gasp of
disgust.
Alright, back on the rails, our current representation of the w-machine state
is simply: s00 s00, nothing on the tape and
a zero bit under the head. How then can we emulate setting the bit under the
head? I swear I did not lie to you earlier when I said each w-machine
instruction takes multiple rules to implement, it is just that we are taking a
shortcut in this particular example. To spoil the surprise, we can simply use
the rule:
s0_0 -> s1_1 s1_1
Now why didn't I use the appendant "s10
s10"? Well we must transition to the NEXT w-machine
instruction. Hopefully those performance implications I mentioned earlier are
starting to calcify. To explain, we must explicitly transform every single
symbol from one state to the next. Every single exponentially increasing symbol
must be artisinally hand-crafted and delivered in order to be consumed by
subsequent states. Dag.
Continuing on with our example, what if we had the w-machine state of
s10 s10 (the bit under the head is a 1
instead of a 0)? Wouldn't we not need to do anything? Keep in mind, it is still
"marked" as being instruction_0's data. How can the next rule operate on it
when the data chooses the rule and the data still belongs to the previous rule!
Even though in one sense it already has the right value, it still must be
updated in order for it to be "visible" to the next instruction. Note, tag
rules are fixed at compile time and they're simply key-value pairs.
Currently we have two rules corresponding with "+":
s0_0 -> s1_1 s1_1
s1_0 -> s1_1 s1_1
This only leaves what to do with tape. In this case, we don't need to modify any other values. This leaves us with only one thing to do: prepare the data for the next instruction! This gives the full ruleset for "+" (as the initial instruction):
x_0 -> x_1 x_1
s0_0 -> s1_1 s1_1
s1_0 -> s1_1 s1_1
y_0 -> y_1 y_1
The implementation for "-" is the same but we replace s1_1 with s0_1. This
means that we are 2/5 of the way there.
Take Your Mind to Another Level
Now let's try our hand at implementing conditional transfer. Remember that we only branch if the bit under the head is set otherwise we fall-through to the next instruction. In the notation we branch to instruction k and are currently emulating instruction i and the next instruction is j = i+1. I'm going to implement this twice. The reasoning behind this will become clear. It is also self-indulgent but I'm pretty proud of this. To spare some typing I'll again follow Wang's lead and list the rules and demonstrate how they work.
But let's slow down for a second. Take a deep breath and ponder this: how can you implement conditional branching given what we know about tag systems? In more ergonomic languages you would have many ways to accomplish conditionals. There are ifs, patterns, cases, jump tables, etc. Unfortunately our toolset is a bit more primitive for the time being. To hopefully put you at ease, I was unable to come up with anything without reading the papers proving universality but thinking about the constraints is useful to appreciate the clever solutions.
Speeding up just a little, the key insight is that the only value that matters is the first deleted symbol. Rephrased, when we delete n-symbols we only use the initial value to perform the lookup. I've been hammering this point for a bit but this grants us the wiggle room we need to unleash that computation magic. One way to exploit this is to unconditionally append BOTH branches. We then use the condition to "jiggle"—or, in the case of the 2-tag system, to change the parity—of the queue. What eventually becomes the initial value is then ordained reality and gets to append what it likes. A quick sketch of this branching idea is to have the "true" condition append an even number of elements while the "false" condition appends an odd number.
That's enough of a warm up, let's see how Wang implemented branching.
(1)
x_i -> t_i t_i
s0_i -> s0'_i
s1_i -> s1'_i s1'_i
y_i -> u_i u'_i
(2)
t_i -> x'_i x''_i
(3)
s0'_i -> x'_i s0''_i s0''_i
s1'_i -> s1''_i s1''_i
u_i -> y'_i y'_i
u'_i -> y''_i y'_i
(4)
x'_i -> x_k x_k
x''_i -> x_j x_j
s0''_i -> s0_j s0_j
s1''_i -> s1_k s1_k
y'_i -> y_k y_k
y''_i -> y_j y_j
Now let's work through the abstract state:
(x_i x_i)^m s0_i s0_i (y_i y_i)^n
by (1), -> (t_i t_i)^m s0'_i (u_i u_i')^n
by (2), -> s0'_i u_i (u'_i u_i)^(n-1) u'_x x'_i (x''_i x'_i)^(m-1) x''_i
by (3), -> (x''_i x'_i)^m s0''_i s0''_i (y''_i y'_i)^n
by (4), -> (x_j x_j)^m s0_j s0_j (y_j y_j)^n
And for s1i:
-> (x_i x_i)^m s1_i s1_i (y_i y_i)^n
-> (t_i t_i)^m s1'_i s1'_i (u_i u'_i)^n
-> (x'_i x''_i)^m s1''_i s1''_i (y'_i y''_i)^n
-> (x_k x_k)^m s1_k s1_k (y_k y_k)^n
Note that when the head is 0 we transition to state j but when it is 1 we transition to state k. Success! Now I highly recommend going through this by hand, rule by rule. You may find something... strange :) Do not fear, because for you, oh dear reader, I shall be your faithful guide. Let's just dive right in.
Let's start very simply and assume we have a completely blank w-machine.
Queue: s0_0 s0_0
s0'_0
ERROR: Queue size is less than deletion number!
Wait, what! That's right, there's an edge case when n=0 ∨ m=0. Note that we must delete 2 symbols per computation step, however when dealing with the empty tape we do not have enough symbols to continue! In the mathematical notation the exponents being 0 is just another value for the tape. It ignores practical constraints on the data representation which, in this case, means the data no longer exists! In the immortal words of Don Knuth, "Beware of bugs in the above code; I have only proved it correct, not tried it." This bug has existed since at least 1962. It is definitely the oldest bug I've ever found. It was around this time that I started using emu/tag.py.
But now we have a big problem. How can we fix this bug so that our compiler no longer emits buggy code? Since the buggy code assumes no disappearence of a symbol, we can add in some filler symbols to ensure this invariant stays true. If you have not stared at the evolving queue of a tag system then here is some intution: before the appendant of a key element can "act" (or execute, or cause side-effects, etc) it must first wait in line. This means that the impact of a given appendant takes time to be felt. We can use this fact to clamp the queue from both ends! What I mean by this is since we know that we just appended a boolean we can then cast a "net" to cover the queue. We catch this net by detecting the parity of the queue.
Let's look at a concrete example of this idea.
Code:
{meta} cond -> net pad test /* This is not a real rule, it's just named
* here to explain the function. Note the
* parity shifting (we queue 3 symbols) */
odd_data -> data /* this is a filler rule just to be exhaustive */
even_data -> data data /* this is a filler rule just to be exhaustive */
net -> oddNet evenNet
oddNet -> /* nothing, the parity is already restored by this point */
evenNet -> pad /* restore the parity */
test -> branchA branchB
data -> /* a multiple of the deletion number */
Data:
0: net pad test data /* note: {net pad test} *IS* cond */
1: test data oddNet evenNet
2: oddNet evenNet branchA branchB
3: branchA branchB
voila
Now let's try it with an even sized data (using the same code as the previous example):
Data:
0: net pad test data data /* note: {net pad test} *IS* cond */
1: test data data oddNet evenNet
2: data oddNet evenNet branchA branchB
3: evenNet branchA branchB
4: branchB pad
voila
Wow! you are clearly screaming. And I agree, this is terrible but such is life. To be explicit, the only thing we are testing for is if the data in the net is even or odd. And by "data in the net" I mean the count of the elements. We will structure the data in the queue to always have even parity (and thus appear "invisible") UNLESS we are performing some conditional branch. This also means that any condition we care about better boil down to parity.
Alright, now let's look at my patch.
(1)
x -> xa xa /* do nothing because we appear before the value
* whose condition we are checking. When the queue
* swings back around then we can spring into action */
s0 -> net blank shift /* cast the net */
s1 -> s1a_t s1a_t /* bask in the glory that the other state has
* to do all the work */
y -> ya_t ya_f /* prep for the parity shift */
(2)
xa -> xb_t xb_f /* now we can prepare for the parity shift */
s1a_t -> s1b_t s1b_t /* keep on trucking, nothing for us to do but
* wait for our moment of glory */
ya_t -> yb_t yb_t /* similarly, just waiting for it to be made official */
net -> blank /* fix up parity */
shift -> s0b_f s0b_f /* looks like there was no 1 underneath */
ya_f -> yb_f yb_f /* waiting for the refs to call it */
(3)
xb_t -> x_t x_t /* and now it's official */
s1b_t -> s1_t s1_t
yb_t -> y_t y_t
xb_f -> x_f x_f
s0b_f -> s0_f s0_f
yb_f -> y_f y_f
Queue: s0 s0
net blank shift
shift blank
s0b_f s0b_f
s0_f s0_f
Queue: s1 s1
s1a_t s1a_t
s1b_t s1b_t
s1_t s1_t
Where _f is the false branch and _t is the desired destination.
The above code has a slightly different style to Wang's. It was copied directly from the source which takes care of the indices automatically. I also do away with primes and label the stages of the "uops" with letters. Thankfully we won't need more than 26, as far as I understand. Wang had the goal of not using more than 3 symbols per appendant. I am not so strict. I was also inspired by this other paper: "Universality of Tag Systems with P=2" by John Cocke and Marvin Minsky. They, likewise, didn't have the 3 symbol appendant limitation.
Implementing Seek
Now we have left and right seek. We'll talk about right but the same ideas apply for left, just mirrored. Before jumping in, let's talk about what exactly seek right entails. We can think of the system as a giant dial with the head at the center. Seeking right therefore shifts every value one slot to the LEFT (this is from the perspective of the head, not the dial). Since the tape is infinite, the head will take on the zero value if the right tape is blank. The old contents of the head are then appended to the left tape. To accomodate this new value every other value in the left tape must be shifted up. This sounds simple enough.
Now let's think about how we can logically accomplish those operations given the tools at hand. First let's examine the left tape. Given some tape contents of m, it becomes m<<1 or 2m. We can perform this by simply doubling the symbols. Next, to append the head we can just add a symbol if it is nonzero or do nothing. This gives us 2m+s. And the left tape has been successfully morphed.
We can now focus on what is necessary for the new value of the head. Thinking back to the dial analogy we see that it is the least significant bit of the right tape. The problem is that the right tape is a homogeneous jumble of symbols. How can we remove a single pair? The clever insight is that our mass of symbols is NOT the unary representation. It is proportional to the unary representation, where the multiple is the deletion number. We can factor out the deletion number and obtain the true unary representation. In this form, the value now effects the parity of the queue and we know how to measure that. Once we perform our measurement we can patch up the tape value and restore anything that we may have squished during the previous step.
Let's look at some code.
(1)
x_i -> xa xa xa xa /* Double the xs */
s0_i -> net _ test
s1_i -> xa xa net _ test
y_i -> ya /* Divide by 2 to obtain the unary representation of the ys */
(2)
xa -> xb xb /* Maintain the status quo so we can do a parity check */
/* Cast the net! This let's us safely operate even if there are no xs or ys
* This senses the parity of the ys. If they're odd, then the new head has a 1,
* if it is even then it gets a 0. */
net -> odd_net even_net
test -> s1b s0b
ya -> yb yb
(3)
xb -> xc xc
s0b -> s0c s0c /* Looks like it was even */
s1b -> s1c s1c /* Turns out we had an odd amount of ys */
odd_net -> /* Print out the intermediate queue, trust me. Keep the odd parity going. */
even_net -> pad /* Print out the intermediate queue, trust me. Balance the parity. */
yb -> yc yc
(4)
xc -> x_j x_j
s0c -> s0_j s0_j
s1c -> s1_j s1_j
yc -> y_j y_j
And two simple examples:
(x x)^0 s0 s0 (y y)^2
0b0 0b0 0b10
Queue:
s0 s0 y y y y
y y y y net _ test
y y net _ test ya
net _ test ya ya
test ya ya odd_net even_net
ya odd_net even_net s1b s0b
even_net s1b s0b yb yb
s0b yb yb pad
yb pad s0c s0c
s0c s0c yc yc
yc yc s0_j s0_j
s0_j s0_j y_j y_j
Or:
(x_j x_j)^0 s0_j s0_j (y_j y_j)^1
0b0 0b0 0b1
And (x x)^1 s1 s1 (y y)^1
0b1 0b1 0b1
Queue:
x x s1 s1 y y
s1 s1 y y xa xa xa xa
y y xa xa xa xa xa xa net _ test
xa xa xa xa xa xa net _ test ya
xa xa xa xa net _ test ya xb xb
xa xa net _ test ya xb xb xb xb
net _ test ya xb xb xb xb xb xb
test ya xb xb xb xb xb xb odd_net even_net
xb xb xb xb xb xb odd_net even_net s1b s0b
xb xb xb xb odd_net even_net s1b s0b xc xc
xb xb odd_net even_net s1b s0b xc xc xc xc
odd_net even_net s1b s0b xc xc xc xc xc xc
s1b s0b xc xc xc xc xc xc
xc xc xc xc xc xc s1c s1c
xc xc xc xc s1c s1c x_j x_j
xc xc s1c s1c x_j x_j x_j x_j
s1c s1c x_j x_j x_j x_j x_j x_j
x_j x_j x_j x_j x_j x_j s1_j s1_j
Or:
(x_j x_j)^3 s1_j s1_j (y_j y_j)^0
0b11 0b1 0b0
Let's take a quick break and get philosophical. We have essentially implemented queues for the x- and y-sides of the tape with nothing but clumps of symbols. The operations were previously described in detail but it is still cool to see such a high level interface emerge from a jumble of rubble.
And we are done! We have implemented every operation and even understand how it works. We are now free to write any program we wish. Well, as long as it is purely functional as the tag system completely lacks IO. But this doesn't have to be the case. Let's extend this antiquated system so that it may post to social media.
Hello World
In the spirit of most esoteric language projects this will only have the ability to read and write to stdin and stdout, respectively. We won't be designing any interrupt mechanisms, unfortunately. With one constraint laid down we must also make certain that our IO system is ergonomic for the tag ecosystem. Since we can't add and remove rules dynamically we're left with operating on the queue. Similarly, the rest of the instructions operate on single bits so our IO methods must as well.
Let's focus on input for the time being. In languages with memory, we'll usually call a function with a buffer of some sort that will be filled with data. In other languages we may call a function that returns some data type that has the corresponding input. What would a tag analogue look like? We could have a rule that appended the input. This seems like a nice idea until we factor in that the tag system doesn't have numbers. Assuming we are reading in an ascii character, how does the input know which rule it corresponds to? The easy answer is that, well, we tell it. The input rule now takes on a special form in that it has TWO appendants, one for a zero bit and one for a 1 bit. The method of receiving input simply chooses the appropriate appendant and off we go.
The notation I chose for this is:
grab_bit -> { received_0 ; received_1 }
We can now turn our attention to output. The same problem of context applies only in reverse. How does the outside world know what data we are trying to show it? And the answer, conveniently, is exactly the same: we tell it. Contrasting with input, however, we only have the one output. This means that we'll need two rules, one per bit. Here is the notation I Chose:
output_0 -> 0: next next
output_1 -> 1: next next
There is a nice symmetry here. The input has two branches while the output joins two separate paths. There may be other ways of performing IO but I am quite pleased with this setup. To solidify it, let's look at cat:
read_bit -> { print0 print0 ; print1 print1 }
print0 -> 0: read_bit read_bit
print1 -> 1: read_bit read_bit
You Are Now a Certified Tag Programmer
And that's it. We now know the tag system inside and out. We can finally discuss how to emulate this thing. The tag emulator has a lot of challenges to overcome if it is to be implementable on real hardware. To read more about my approach, I'll eventually post something covering an interpreter.
For completeness, here are the rules I used in my w-machine -> tag compiler (which you can also find in Rust/wmach/src/lib.rs):
+: // Set
x_start -> x x
s0_start -> s1_next s1_next
s1_start -> s1_next s1_next
y_start -> y y
-: // Unset
x_start -> x x
s0_start -> s0_next s0_next
s1_start -> s0_next s0_next
y_start -> y y
>: // Seek Right
//
// (1)
//
// Double the xs
x -> xa xa xa xa
s0 -> net blank test
s1 -> xa xa net blank test
// Divide by 2 to obtain the unary representation of the ys
y -> ya
//
// (2)
//
// Maintain the status quo so we can do a parity check
xa -> xb xb
// Cast the net! This let's us safely operate even if there are no xs or ys
net -> odd_net even_net
// This senses the parity of the ys. If they're odd, then the new head has a 1,
// if it is even then it gets a 0.
test -> s1b s0b
ya -> yb yb
//
// (3)
//
xb -> xc xc
// Looks like it was even
s0b -> s0c s0c
// Turns out we had an odd amount of ys
s1b -> s1c s1c
// Print out the intermediate queue, trust me. Keep the odd parity going.
odd_net ->
// Print out the intermediate queue, trust me. Balance the parity.
even_net -> pad
yb -> yc yc
//
// (4)
//
xc -> x_next x_next
s0c -> s0_next s0_next
s1c -> s1_next s1_next
yc -> y_next y_next
<: // Seek Left
// SeekOp::Right was done first so the comments there will be better. This is
// the same exact idea only mirrored.
//
// (1)
//
// Maintain the status quo
x -> xa xa
s0 -> net blank test
s1 -> net blank test ya ya
// Double
y -> ya ya ya ya
//
// (2)
//
// Halve
xa -> xb
// Cast the net so we can operate even with no xs or ys.
net -> odd_net even_net
test -> s1b s0b
ya -> yb yb
//
// (3)
//
xb -> xc xc
s0b -> s0c s0c
s1b -> s1c s1c
odd_net ->
even_net -> pad
yb -> yc yc
//
// (4)
//
xc -> x_next x_next
s0c -> s0_next s0_next
s1c -> s1_next s1_next
yc -> y_next y_next
,: // Input
x -> x_next x_next
s0 -> { s0_next s0_next ; s1_next s1_next }
s1 -> { s0_next s0_next ; s1_next s1_next }
y -> y_next y_next
.: // Output
x -> x_next x_next
s0 -> 0: s0_next s0_next
s1 -> 1: s1_next s1_next
y -> y_next y_next
jmp _t, _f: // if *head { goto _t } else { goto _f }
//
// (1)
//
// Since the xs appear before the head (s*), we maintain the status quo for a cycle so
// that we can be impacted by the parity flip.
x -> xa xa
s0 -> net blank shift
s1 -> s1a_t s1a_t
y -> ya_t ya_f
//
// (2)
//
// Ok, now we can participate in the parity flip.
xa -> xb_t xb_f
s1a_t -> s1b_t s1b_t
ya_t -> yb_t yb_t
net -> blank
shift -> s0b_f s0b_f
ya_f -> yb_f yb_f
//
// (3)
//
xb_t -> x_t x_t
s1b_t -> s1_t s1_t
yb_t -> y_t y_t
xb_f -> x_f x_f
s0b_f -> s0_f s0_f
yb_f -> y_f y_f