Hello! In this series of articles I'll be covering an implementation of a toolchain (including various emulators) for an obscure turing-tarpit called the tag system. This is an intense rambling path with many rest-stops to view the scenery. Some highlights include finding a 60 year old bug (and fixing it), at least 3 frameworks of parsers, multiple compilers spanning multiple implementation languages targetting various intermediate languages, many interpreters with varrying levels of debuggability and speed, and, of course, an immense array bugs in absurd quantity and variety. The project still is yet completed but most of the major components are in place.
You may be wondering why I set out on this journey in the first place. The answer is essentially "because it is awesome", as one might expect. This is what adventure looks like. I hope that you'll agree with me by the end of this series.
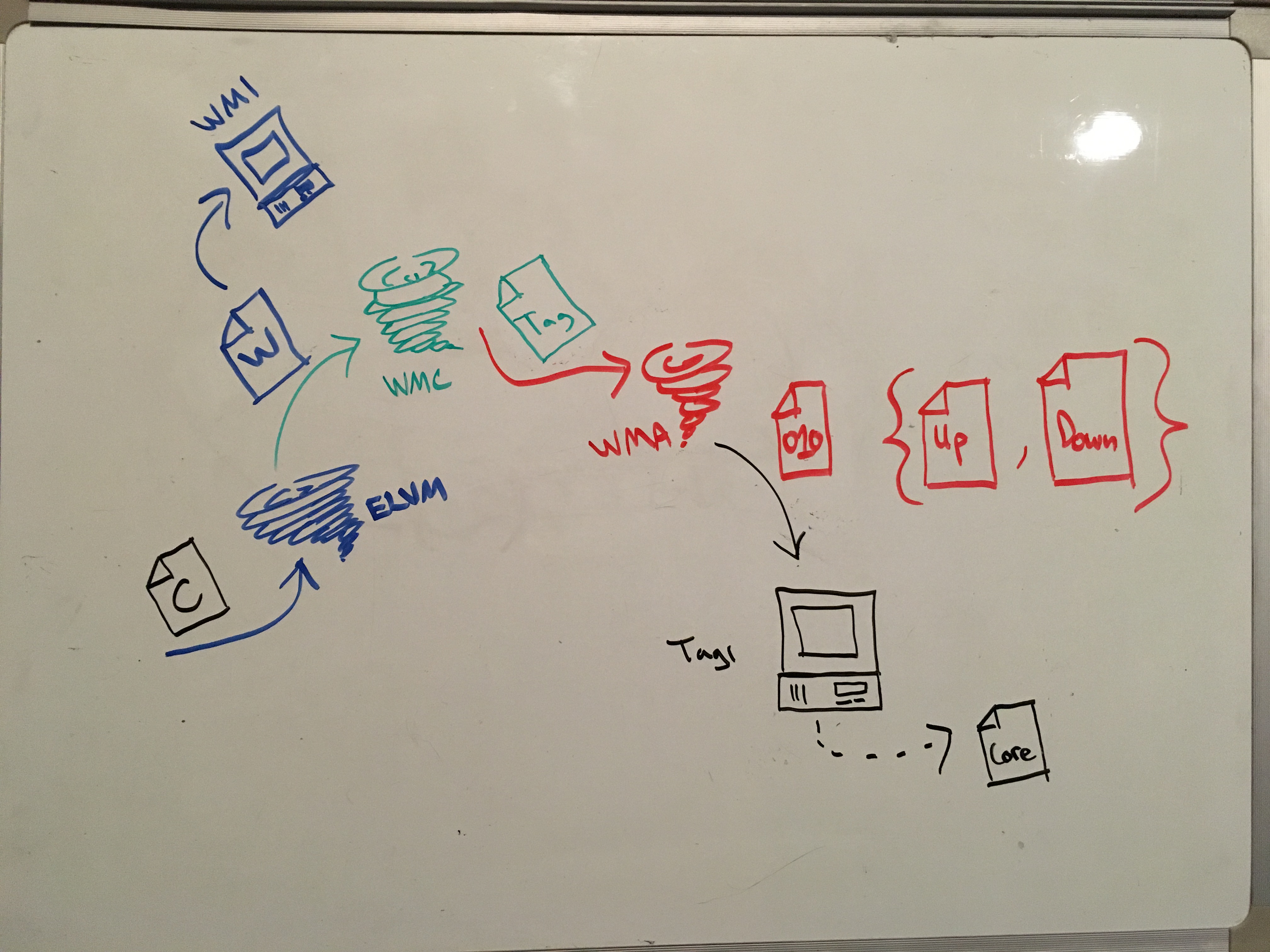
The whole series will be posted to the category: spelunking in the turing tarpit. Check there (or the rss feed) for new entries. Roughly, the content will include describing the tag system in pretty good detail. We will focus on Hao Wang's proof of computability as that is what I spent the most time on though other proofs will be referenced. Once we firmly understand what makes these things computable we can dive into an interpreter. There are a few of them but the one we'll cover likely will have some spiffy optimizations that make the exponential time and space much more manageable. To generate data for the interpreter we will of course need a compiler so we'll have to cover some compilers and their parsers. I started with haskell but eventually moved to rust so this will only cover the end result. Writing w-machine code by hand is pretty tiring so we'll need another level of compiler to generate this for us and this is where ELVM comes in. I'll likely add a conclusion article that nicely let's you know you can stop reading.
Now that we have the map laid down I can ramble a bit. Tag systems! What a ridiculous computer. These things are used in all kinds of extremely esoteric nonsense. Ever wondered how Matthew Cook proved rule-110 was turing complete? Me too, but I know it involves something about simulating a tag system, eventually. But this is not all, a bunch of computer nerds deploy these machines in all manner of nooks and crannies across the computing landscape to demonstrate just how rich in computation we are nowadays. I trust this is enough evidence to convince even the most ardent skeptic of the usefulness of this work.
When I first read the wikipedia article on tag systems I thought "how do you write a program for this?" I casually searched around but was unable to find anything giving insight. I then searched a bit less casually and asked around on the esolang IRC but the replies focused on implementing an interpreter and not programming the tag system. At this point I began to read through the proofs of turing completeness. The proofs were so good that I felt comfortable writing real tag programs. But before you can write the program, you need the emulator to test it. And before you can debug the emulator you need programs to excise the proper paths. And to get these programs you need to generate them from easier programs. Eventually you're writing an emulator for an intermediate language so that you can debug your compiler in order to debug your interpreter in order to debug your compiler.
And that is where I left off a while ago until I had a neat idea. Instead of trying to interpret these massive programs I could reflect them back into C and use a "real" compiler. In this way I would be granted all of the benefits of a traditional toolchain including being able to use a debugger. I threw something together and had an issue debugged in a few minutes. Never doubt the power of a short feedback loop! Now the compiler backend was complete and the rest of the project began to flow again.
But I am getting ahead of myself. Let's start from the beginning. Let's examine The Tag System.